A Note on Branching Within a Shader
An eternity ago, I published a blog post about a shader I wrote. In that post, I casually repeated a piece of gpu folklore I picked up as a wee opengl enthusiast almost a decade ago,
"Using if statements inside a shader will cause performance degradation."
People on the internet seemed a little skeptical about this statement, and I realized my advice might be outdated. So this post is a quick follow up about the cost of branching on more modern gpus.
Before we talk about branching, what is a gpu? A GPU or graphics processing unit, is a special piece of hardware initially developed to crunch numbers for graphics calculations. It accomplishes this goal quickly through a large amount of parallelization.
GPUs can run many threads at the same time in parallel. These threads are generally executed in groups called warps (CUDA), invocations (Vulkan) and waves (I will use the term warp, but they are all interchangeable). On recent Nvidia hardware (Ampere/ Volta / Pascal) these warps contain 32 threads. Pascal for example can theoretically run up to four independent instructions per warp over 56 warps of 32 threads which comes out to a mind blowing 7168 instructions per cycle.
Each warp can only execute one instruction at a time. However that instruction can be executed for each of the threads in the warp. This means the GPU can execute 32 copies of the same instruction in parallel for each thread in the warp at once.
However, taking both sides of a branch will cause the threads inside a warp to "diverge". This means some threads will need to execute one side of the branch and some will need to execute the other. Unfortunately, both instructions can not be executed simultaneously for threads in the same warp. So these divergent instructions must be executed sequentially.
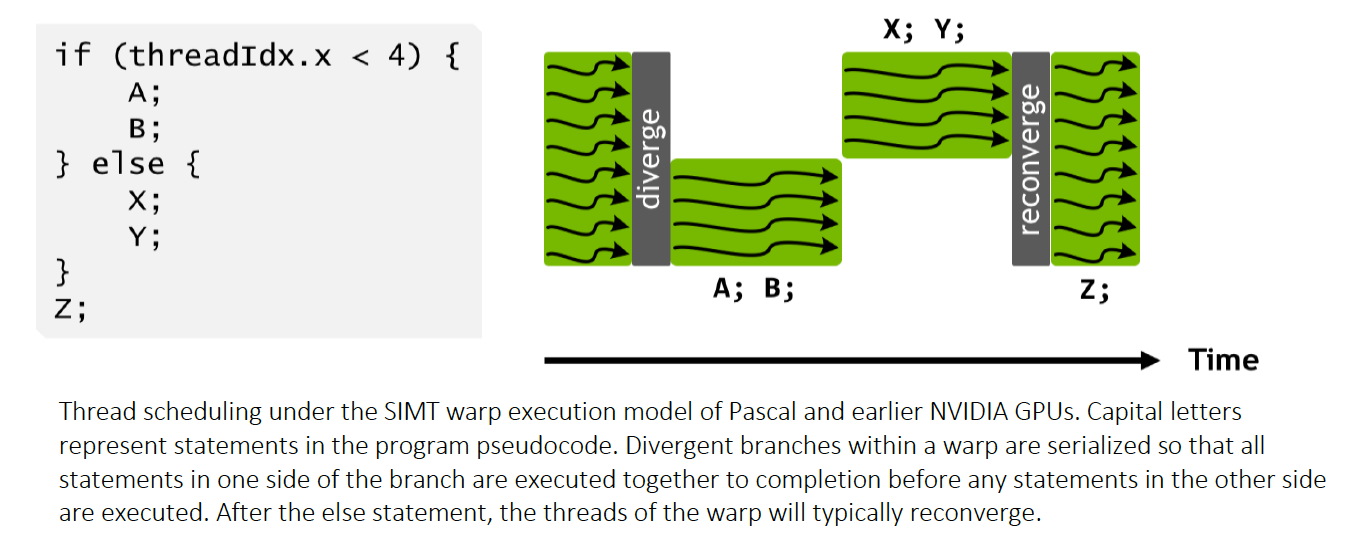
The above image is taken from the Volta whitepaper.
Consider the following fragment shader:
void mainImage( out vec4 fragColor, in vec2 fragCoord )
{
}
In fragment shaders like the one above, each warp is composed of a set of spatially close pixels. Each warp in this shader should diverge because each horizontally adjacent pixel takes a different side of the branch. Let's say the cost of each inner loop is n cycles. Since each side of the branch is executed in series, each warp must take at least 2n cycles, even though each thread uses only one side of the branch. These effects scale with the number of threads in the distinct divergent paths taken (up to 32x in Nvidia hardware). Here's another shader which should have roughly four branches per warp. This shader will take at least 4n cycles.
However, let's look a second shader:
void mainImage( out vec4 fragColor, in vec2 fragCoord )
{
}
This shader should run roughly twice as fast as the other shader even though roughly the same number of pixels take each branch. This is because most of the warps do not diverge (with the exception of a few around half way across the screen).
Nvidia Specifics
As far as I can tell, there are roughly two different ways of nvidia graphics cards handle divergence with in a warp.
Thread Masking (Pre Volta)
On pre volta Nvidia card, divergence was handled by something called thread masking.
Basically when a conditional is hit, a thread mask is generated. We can think of this mask as a 32 entry array. Each entry specifies whether the corresponding thread takes the first side of the branch or not. The first side is then executed for each of those threads. After the first side of the branch is then executed, the mask is reversed and the other side of the branch is executed.
This thread mask strategy exists in part because there is only one program counter per warp on pre volta gpus. So essential every thread in the warp must be at the same place in the program. The only way we know which threads to execute, is by using the mask.
The above image is taken from the Volta whitepaper.
It's worth noting that only the threads which need to execute the branch actually are assigned to computational cores. So if no threads execute one side of the branch, no work is done.
Independent Thread Scheduling (Volta and Beyond)
One big change in the Volta architecture and beyond is the introduction of "Independent Thread Scheduling".
In Independent thread scheduling, each thread has its own program counter. This allows each warp to track the execution of every thread at a fine grain level. However, we can still only execute only one instruction at a time. So the actual runtime of a branch does not change.
So if Independent Thread Scheduling does not speed up branching, what does it do? Independent Thread Scheduling enables both sides of a branch to execute concurrently but not in parallel.
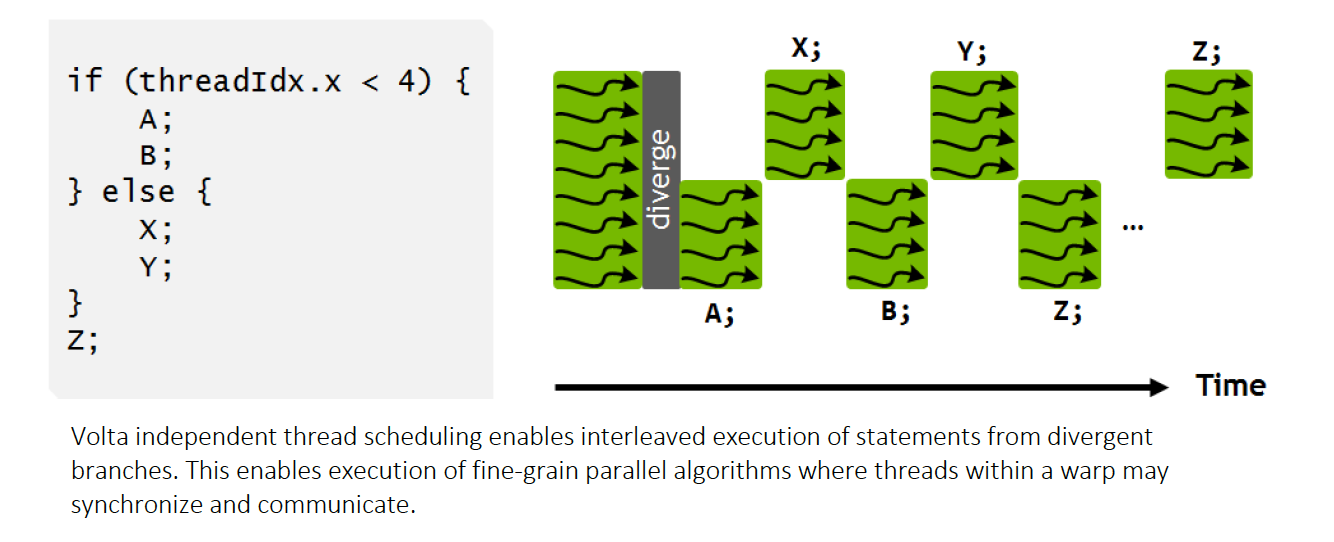
The above image is taken from the Volta whitepaper.
The reason for this shift is because before Volta, branches were places where deceptive deadlocks could occur.
leader_id = 0
If (threadIdx.x == leader_id) {
} else {
}
In the above compute shader pseudo code, we have 31 "follower" threads waiting for the "leader thread" to finish (using in-warp shared local memory) before executing their own instructions.
On a Pascal GPU or below, if the else side of the branch is executed first, a deadlock will occur. The leader will never get a chance to start it's work because its followers will be waiting for it.
Independent Thread Scheduling gets around these locking problems by interlacing the two diverging paths.
Article TLDR
Branch divergence in warp makes all parts of the branch execute in sequence which slows down the shader. Branching divergence between warps does not affect runtime.
Further Reading
Branch execution on gpus is surprisingly deep, and there are many edge cases I didn't address and I also didn't touch gpu vendors other than Nvidia. Here are some good sources if you want to learn more:
The Volta Whitepaper (Most of this post can be found between figures 20 and 22)
Understanding the Pascal GPU Instruction Pipeline
What's up with My Branch on GPU (this post covers some diabolical edge cases, including some around texture sampling)
Have questions / comments / corrections?
Get in touch: pstefek.dev@gmail.com